Program
Conference Program
Date: April 10-12, 2026
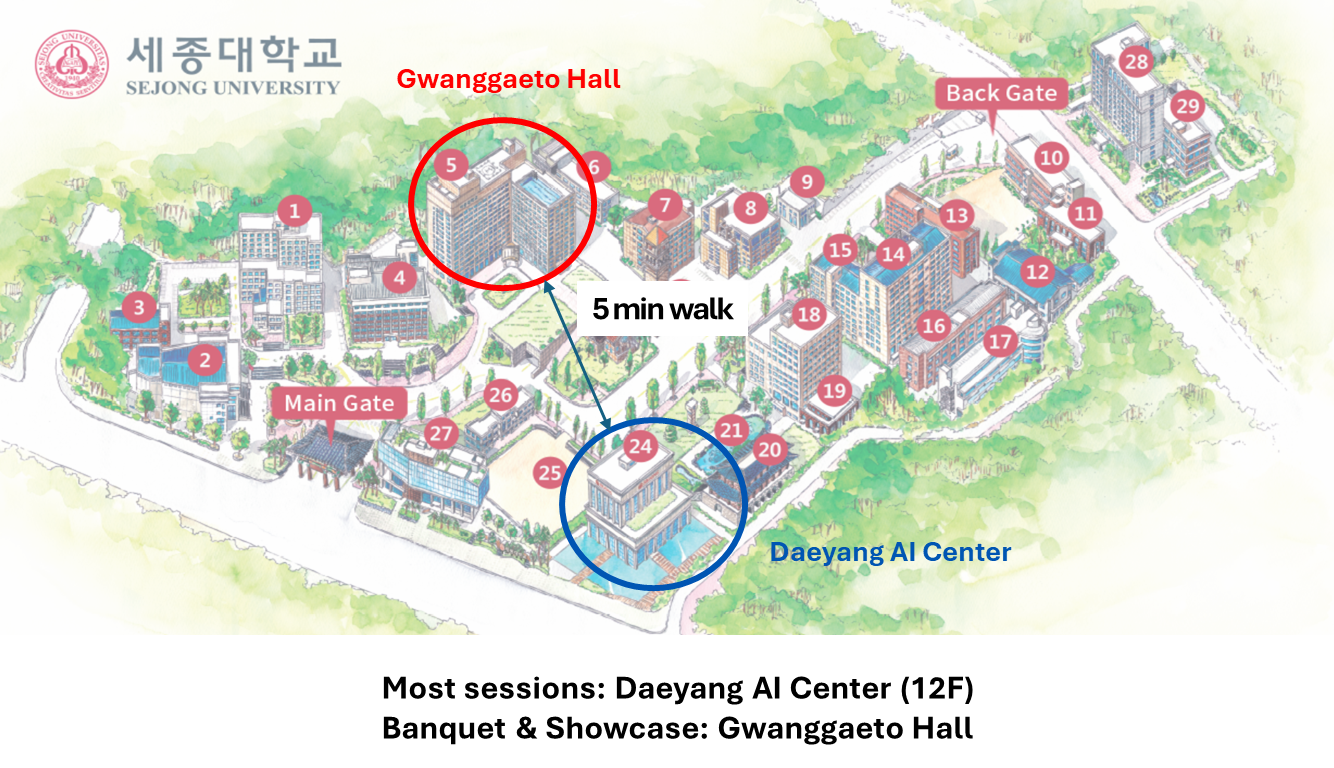
Venue: Daeyang AI Hall (12F), Sejong University
Please note: All times are local time (KST, UTC+9).
PowerPoint Template for Authors: Download Presentation Template (ZIP file containing slide templates for all presenters)
| Day 1 | Friday, April 10, 2026 |
| 08:30 - 09:00 | Registration @ 12F, Daeyang AI Center |
| 09:00 - 09:20 | Opening Session: Opening Remarks by Conference Chair Welcome Address by the President of Sejong University (Chair: Soo-Mi Choi) |
| 09:20 - 10:20 | Keynote Speech I - Prof. Seung-Hwan Baek: Computational Illumination for High-dimensional Visual Computing (Chair: Carol O'Sullivan) |
| 10:20 - 10:40 | Coffee Break |
| 10:40 - 11:55 | Paper Session 1: 3D Gaussian and SLAM (Chair: Taijiang Mu) |
| Tongtai Cao, Shi-Sheng Huang, Kaiyue Guo, Hao Sha, Deqi Li, Yue Liu MGS-SLAM: Monocular 3D Gaussian Splatting SLAM with Significance-Guided Pruning |
|
| Zhexi Peng, Kun Zhou, Tianjia Shao Gaussian-Plus-SDF SLAM: High-Fidelity 3D Reconstruction at 150+ fps |
|
| Lifan Wu, Ruijie Zhu, Yubo Ai, Tianzhu Zhang SkeletonGaussian: Editable 4D Generation through Gaussian Skeletonization |
|
| Ling-Xiao Zhang, Chenbo Jiang, Yu-Kun Lai, Lin Gao SeG-Gaussian:Segmentation-Guided 3D Gaussian Optimization for Novel View Synthesis |
|
| Likun Gao, Yijun Feng, Shibang Xiao, Xiaohui Liang Occlusion‑Aware 3D Gaussian Splatting for Real‑Time Inverse Rendering |
|
| 11:55 - 13:00 | Lunch @ BigBear (2F) |
| 13:00 - 13:50 | Invited Session 1: Spotlight on Leading Research Centers in Visual Media (Chair: Jungdam Won) |
| Prof. Young J. Kim (Ewha Womans University, Korea) Physical simulation meets physical AI |
|
| Prof. Shi-Min Hu (Tsinghua University, China) Graphics research at Tsinghua University |
|
| Prof. Seungyong Lee (POSTECH, Korea) Graphics Research at POSTECH |
|
| Prof. Junyong Noh (KAIST, Korea) Research on 3D Avatar Creation (performed at VML KAIST) |
|
| Dr. Ilkwon Jeong (ETRI, Korea) Introducing ETRI's Content Research Division: Past, Present, and Future |
|
| 13:50 - 14:05 | Coffee break |
| 14:05 - 15:05 | Paper Session 2: Advances in Augmented and Extended Reality (Chair: HyungSeok Kim) |
| Yi-Jun Li, Hao-Zhong Yang, Wen-Tong Shu, Miao Wang Semantics-Aware Avatar Locomotion Adaption for Indoor Cross-Scene AR Telepresence |
|
| Taewoo Jo, Ho Jung Lee, Sulim Chun, In-Kwon Lee Manual-Free Gaze Interaction via Bayesian-Based Implicit Intention Prediction |
|
| Suemin Jeon, JunYoung Choi, Haejin Jeong, Won-Ki Jeong XROps: A Visual Workflow Management System for Dynamic Immersive Analytics |
|
| Yeeun Kim, Phil Joong Kim, Soo-Mi Choi Bridging Real and Virtual in XR Editing: Color Extraction and Contextual Placement |
|
| 15:05 - 15:20 | Coffee Break |
| 15:20 - 17:00 | Paper Session 3: Visual Intelligence: Generation, Optimization, and Beyond (Chair: Jae-Pil Heo) |
| Meng-Hao Guo, Chen Wang, Wei Liu, Shi-Min Hu FastMAE: Efficient Masked Autoencoder with Offline Tokenizer |
|
| Haoran Mo, Yulin Shen, Edgar Simo-Serra, Zeyu Wang DoodleAssist: Progressive Interactive Line Art Generation With Latent Distribution Alignment |
|
| Fuyi Yang, Mingqian Zhang, Yanshun Zhang, Jiazuo Mu, Junxiong Zhang, Lan XU, Yingliang Zhang CADSpotting: Robust Panoptic Symbol Spotting on Large-Scale CAD Drawings |
|
| Short Break (10 min) | |
| Hongyang Zhou, Jingyan Qin, Liuling Chen, Junyi He, Xiaobin Zhu Unsupervised Real-World Image Super-Resolution via Rectified Flow Degradation Modeling |
|
| Zhenhu Zhang, Ruofeng Tong, Lanfen Lin, Yen-Wei Chen FedDTR: Leveraging intra-domain global priors via Domain-Invariant Text Representation for Personalized Federated Learning |
|
| Peng Zheng, Yi Chang, Yilin Wang, Rui Ma A 3D-Consistent Super-Resolution Framework for Efficient and Enhanced 3D-Aware Image Synthesis |
|
| 17:00 - 17:10 | Short Break |
| 17:10 - 18:00 | Poster & Technical Briefs Session 1: FastForwards @ 12F, Daeyang AI Center (Chair: Sang Il Park) 📍 Fast-Forward (poster only): Daeyang AI Hall, 12F 📍 Poster & Technical Brief presentations: Lobby, 12F |
| [P1] Sen Tao, Jiawei Liu, Yongchao Xu, Guangxi Wan, Peng Zeng Mining the Potential of Rehearsal Mechanism for VLM-based Class Incremental Learning |
|
| [P2] Xingrui Liu, Ying Song Structure-aware joint low-light image enhancement and deblurring in the HVI space |
|
| [P3] Xufan He, Dong Du, Yushuang Wu, Yunbi Liu NGR: Neural Gradient Rendering for High-Quality 3D Reconstruction from Multi-View Images |
|
| [P4] Renlong Dai, Zongxin Shang, Jiarui Li, Linbo Wang, Zhengyi Liu, Xianyong Fang HGM: Human Gaussians to Mesh by Adaptive Optimization |
|
| [P5] Jiarui Li, Zongxin Shang, Renlong Dai, Linbo Wang, Zhengyi Liu, Xianyong Fang ShareUs: A Unified System for Multi-avatar Reconstruction and Editing |
|
| [P6] Zongxin Shang, Renlong Dai, Jiarui Li, Linbo Wang, Zhengyi Liu, Xianyong Fang HiAvatar: High-Fidelity Reconstruction of Avatars by Spatial and Temporal Enhancement |
|
| [P7] Lifei Xiao, Zhenjie Zhao GNFM: Generalizable NeRF with View-Aware Feature Modulation for Reflective Surgical Instrument Rendering toward Robot-assisted Surgery |
|
| [P8] Kai Liu, Chuanqi Tao MGCL: Modality-Granularity Collaborative Contrastive Learning for Multimodal Sentiment Analysis |
|
| [P9] Yiping Yang, Yingming Li Multimodal Video Ordering via Task-Specific Pre-Training and Alignment-Guided Fine-Tuning |
|
| [P10] Mengke Li, Haiquan Ling, Yiqun Zhang, Yang Lu, Hui Huang Learning from Imperfect Text Guidance: Robust Long-Tail Visual Recognition with High-Noise Labels |
|
| [P11] Kai Xiong, Siyu Wu, Xiyu Pan, Jianjun Li Adverse Weather Image Restoration with Multi-domain Collaborative Guidance |
|
| [P12] MengYi Lv, Yafeng Zhao, Wanqi Cheng, Gang Shi Sphere-CenterNet: A Geometry-Aware Center-based Detection on ERP Images |
|
| [P13] Bohan Wang, Tianwu Lei, Silin Chen, Shurong Cao, Ningmu Zou Texture-AD: An Anomaly Detection Dataset and Benchmark for Real Algorithm Development |
|
| [P14] Meng Yuan, Dawei Lin, Tongyuan Bai, Tieru Wu, Rui Ma UniCAD: A Prototype-Enhanced Unified Framework for CAD Construction Sequence Generation |
|
| [P15] Yuanzhen Li, Fubao Yang, HongZhi Liu, Fengli Yang, Leran Ye, Yue Zhao, Xiaoxiao Wang Dark Channel Prior Guided Semi-Supervised for Text Image Restoration Under Specular Highlights and Blur |
|
| [P16] Jinghao Shi, Jianing Song BiCoR-Seg: Bidirectional Co-Refinement Framework for High-Resolution Remote Sensing Image Segmentation |
|
| [P17] Yiran Li, Dongdong Zhao, Peng Chen, Fuling Huang, Weibo Mao MetaSegNet: An Edge Computing-Oriented Meta-Learning Method for Few-shot Sonar Image Segmentation |
|
| [P18] Xin Chen, Qingzhen Xu, Mingyu Liu, Junbin Yuan Global-Local Multi-scale Fusion Network for RGB-D Salient Object Detection |
|
| [P19] Yi Wang, Yinfeng Yu, Bin Ren Residual Cross-Modal Fusion Networks for Audio-Visual Navigation |
|
| [P20] Jianlou Lou, Aodi Ye, Jianxun Lou MCDI-CVL: Multi-crop Disease Identification Model Based on Cross-modal Visual Language Feature Fusion |
|
| [P21] Gang Li, Yijun Lin, Kairu Zhang, Ling Zhang, Hao Liu FreqMamba-UNet with Dual-Path Fusion and Multi-Scale Feature Interaction: Segmentation of Ground-Glass Opacities and consolidation in Lung CT |
|
| [P22] Qixi Zhao, Jiwei Nie, Zuotao Ning, Joe-Mei Feng MGGA: Make GeM Great Again via Regularization Branch to Mitigate Channel Vanishing in Visual Place Recognition |
|
| [P23] Yuanhao Zheng, Sixian Chan, Jie Hu PMPTrack: A Decoupled Two-Stage Progressive Modality Promotion Paradigm for RGB-T Tracking |
|
| [P24] Qi Zheng A Hybrid Pipeline for Large-Scale PCB Modeling |
|
| [P25] Li Ye, Xinhang Zhou, Xingyu Yang, Peng Fan, Ruofeng Tong, Hailong Li, Peng Du, Min Tang gMidSurf: Hierarchical GPU-based Mid-surface Abstraction for Thin-walled CAD Models |
|
| [P26] Kaichen Liu, Fazhi He, Rubin Fan, Yuxin Liu, Wan Ruibo, Jianfei Liang, Lei Yixiang Less is More: Learning Compact and General CSG Representations via Algebraic Normal Form |
|
| [P27] Yinyin Hu, Kaining Ying, Henghui Ding Video Instance Segmentation via Bidirectional Mask Propagation with SAM2 |
|
| [P28] Diwei Wu, Jun Liu, Jian Liu, Hewen Liu, Jun Yang ArTex: Artist-Sensitive Style Transfer via Textual Guidance |
|
| [P29] Zijin Guo, Suya Li, Zhenping Xie MVBeautyFusion:A Continuous-view Fusion Framework for Face Structure Beautification |
|
| [P30] Qi-Yuan Feng, Taijiang Mu, Shi-Min Hu Gaussian4Triplane: Gaussian Feature Network for Triplane based 3D Large Reconstruction Model with Very Few Parameters |
|
| [P31] Qifeng Chen, Sicong Du, Tao Tang, Rengan Xie, Peng Chen, Yuchi Huo, Sheng Yang LiDAR-GS: Real-time LiDAR Re-Simulation using Gaussian Splatting |
|
| [T1] Minseok Oh, Siyeon Park, Seungmin Kim, Wonhee Kim, Hojin Lee RT-MP3D: A Lightweight Real-Time Framework for Multi-Person 3D Pose Estimation from Monocular Video |
|
| [T2] Hui Zhao Computational Discrete Global Geometric Structures |
|
| [T3] Hui Zhao Super Structured Quad Mesh |
|
| [T4] Md Mridul Hossain, SeongKi Kim PSNR vs. FPS: The Ultimate Trade-off in Real-Time Gaussian Splatting |
|
| [T5] Hui-jun Kim, Sung-Hee Kim Fine-tuning the Segment Anything Model for Prompt-based Instance Segmentation in Footwear Design |
|
| [T6] Ziang Lu, Kai Zhang, Dong Liang, Jinyuan Jia ParaForest: A Unified Framework for Real-time Massive Web3D Forest Generation and Rendering |
|
| [T7] SeokMin Hong, Doyeon Han, Oh-Young Song Image Style Transfer based on Neural Cellular Automata |
|
| [T8] Sang-Heon Oh, Sung-Hee Kim Design of a Pattern Extraction and Nesting Pipeline Based on Multi-View 2D Shoe Images |
|
| [T9] Tai Inui, Alex Matsumura, Edgar Simo-Serra Geodiffussr: Generative Terrain Texturing with Elevation Fidelity |
|
| [T10] Seunghyeon Son, Sanghun Park VPS-based Book Retrieval for Smart Devices |
|
| 18:00 - 18:10 | Shuttle Bus Departure for the Reception |
| 18:30 - 20:30 | Welcome Reception @ Seoul Brewery in Seongsu & GO! TORI |
| Day 2 | Saturday, April 11, 2026 |
| 08:30 - 09:00 | Registration @ 12F, Daeyang AI Center |
| 09:00 - 10:00 | Keynote Speech II - Prof. Beibei Wang: The Evolution of Material Representation: From Physically-Based to Neural Networks (Chair: Oh-young Song) |
| 10:00 - 10:20 | Coffee Break |
| 10:20 - 12:00 | Paper Session 4: 3D Geometry Processing and Reconstruction (Chair: Yuanfeng Zhou) |
| Xue-Kun Xiang, Yu-Jie Yuan, Wen-Bo Hu, Yu-Tao Liu, Yue-Wen Ma, Lin Gao PGT-NeuS: Progressive-Growing Tri-Plane Representation for Neural Surface Reconstruction |
|
| Bingxi Liu, An Liu, Hao Chen, Huaqi Tao, Jinqiang Cui, Yiqun Wang, Hong Zhang MT-PCR: Hybrid Mamba-Transformer Network with Spatial Serialization for Point Cloud Registration |
|
| Juan Fang, Jian Liu, Lei Wu, Manyi Li BiPart: Bi-level Optimization for Generalizable 3D Part Segmentation Prior Distillation from Pre-trained Vision-Language Model |
|
| Short Break (10 min) | |
| Jiaxiang yao, Dan Zhang, Dong Zhao, Jianmin Zheng GeoSe-FMap: Geometry–Semantic Functional Maps for Unsupervised Cross-Modal Deformable 3D Shape Correspondence |
|
| Yiming Luo, Abhijeet Ghosh Faithful Single Image Face Reconstruction Using GAN Inversion |
|
| Yibo Kou, Xin Li, Ma Hong-yu, Liyong Shen, Chunming Yuan A Generalized NURBS Framework with Globally $G^2$ continuity |
|
| 12:00 - 13:00 | Lunch @ BigBear (2F) |
| 13:00 - 13:40 | Industry Session: Industry Perspectives on Visual AI (Chair: Seungyong Lee) |
| Toonsquare (CEO Hoyoung Lee) AI Webtoon Production Pipeline with Tooning Plus |
|
| DiBlAT (CEO Wanho Choi) Next-Generation Video-to-Video Pipeline: A Gaussian Splatting Approach |
|
| Deeping Source (CEO Taehoon Kim) Vision-based Spatial Agentic AI in Retail Industry |
|
| Anigma Technology Inc. (CEO Kyungmin Cho) Development and Application Cases of AI Models Using Facial Data |
|
| 13:40 - 13:55 | Coffee Break |
| 13:55 - 14:40 | Paper Session 5: 3D Scene Understanding and Generation (Chair: Manyi Li) |
| Shao-Kui Zhang, Liang Yue, Haoran Zhang, Han-Xi Zhu, Yong-Liang Yang, Song-Hai Zhang SceneCluster: Interactive Scene Synthesis by Clustering Groups of Furniture Objects |
|
| Clément Jambon, Changwoon Choi, dongsu zhang, Olga Sorkine-Hornung, Young Min Kim ExCellGen: Fast, Controllable, Photorealistic 3D Scene Generation from a Single Real-World Exemplar |
|
| Yu-Qi Yang, Yu-Xiao Guo, Jian-Yu Xiong, Yang Liu, Hao Pan, Peng-Shuai Wang, Xin Tong, Baining Guo Swin3D: A Pretrained Transformer Backbone for 3D Indoor Scene Understanding |
|
| 14:40 - 14:55 | Coffee Break |
| 14:55 - 16:10 | Paper Session 6: AI for Creative Applications (Chair: Ping Li) |
| Dong-Yang Li, Yi-Long Liu, Zi-Xian Liu, Yan-Pei Cao, Meng-Hao Guo, Shi-Min Hu SeparateGen: Semantic Component-based 3D Character Generation from Single Images |
|
| Fangtian Liang, Guangshun Wei, Pengfei Wang, Zheng Bi, Yuanfeng Zhou DoubleGaussianAvatar: Double Gaussians for Driveable Head Avatars with Dynamic Facial Details |
|
| Yu Liu, Qiu Huawei, Chao Liu, Yang Ding, Yuqiu Kong, Cunrui Wang Write Freely: Disentangling Content and Style for Multi-Scale Autoregressive Reconstruction of Online Handwriting Trajectories |
|
| Mingi Yeom, Rim Soo Shin, Sung-Hee Lee GarmentoPIA: Generating Garment Pattern Models using Intelligent Agents |
|
| Guoqing Yang, Haoyuan Lv, Mengke Li, Ke Xie, Hui Huang Urban3A: Active Annotation Assisted Semantic Segmentation of Large-scale Urban Scenes |
|
| 16:10 - 16:25 | Group Photo and Coffee Break |
| 16:25 - 17:15 | Poster & Technical Briefs Session 2: FastForwards @ 12F, Daeyang AI Center (Chair: HyeongYeop Kang) 📍 Fast-Forward (poster only): Daeyang AI Hall, 12F 📍 Poster & Technical Brief presentations: Lobby, 12F |
| [P32] Jiayan Dai, Zhihui Lai, Kong Heng IntraSense-Net: A Breast Tumor Ultrasound Image Segmentation Method with Semantic Differentiation |
|
| [P33] Yimeng Shan, Haicheng Qu Spiking Neural Networks with Asynchronous Spatiotemporal Attention for Neuromorphic Vision |
|
| [P34] Zhao Tongzheng, Yan Chen, Liang Du Fairness-Aware Late-Fusion Multi-View Clustering with Balance and Robustness |
|
| [P35] Yuncong Liu, Wang Xiaogang, Yu Zhang, Kai Xu RoofIt: 2D Parametric Sketch Extraction from Rough Models for High-quality Roof Reconstruction |
|
| [P36] Wanchuang Luo, Fangbo Lu, Yongyuan Qiao, Meili Wang DiCo-Net: A Two-Stage Diffusion-Convolution Network with Multimodal Fusion for High-Resolution line-art Extraction |
|
| [P37] Jiaxin Yang, Wenbo Liu, Tao Deng, Fei Yan SD-Net: Synergistic and Dynamic Learning for Small Object Detection in Aerial Images |
|
| [P38] Feifei Xu, Yu Xie, Dongyang Li, luobin Huang, Zhihao Guo LME-DETR: Lightweight and Multi-Scale Feature-Enhanced End-to-End Object Detection for Aerial Images |
|
| [P39] Nobuo Nakagawa, Takashi Kanai Precomputed Mesh Optimization Using Modal Analysis for Elastic Body Simulations |
|
| [P40] Atsushi Maruyama, Sosui Koga, Akinobu Maejima, Yuki Koyama, I-Chao Shen, Takeo Igarashi LayerPack: Cross-Layer Consistency in Animation Inbetweening |
|
| [P41] Zhao Tongzheng, Yan Chen, Liang Du Scalable and Principled Fairness in Fuzzy Clustering |
|
| [P42] Huiyang Li, Yongwei Nie, Hushan Song, Ping Li Pose-Free 3D Gaussian Splatting for Orderded and Unordered Frame Sequence Scene Reconstruction |
|
| [P43] Hao Feng, Zhi Zuo, Jia-Hui Pan, Ka-Hei Hui, Jingyu Hu, Qi Dou, Zhengzhe Liu WonderVerse: Video Geometric Correction and Enhancement for Extendable 3D Scene Generation |
|
| [P44] Jinsong Zhang, I-Chao Shen, Jotaro Sakamiya, Yuqin Lin, Yu-Kun Lai, Takeo Igarashi, Kun Li CleanAvatar: Artifact-free Gaussian Avatar via Mesh Guidance and Segmentation-driven Augmentation |
|
| [P45] Xiasi Wang, Jiale Zheng, Jianfeng Zhang, Yi Huang, Lujia Pan, Runqi Wang Memory-Aware Replay and Loss Balance for Long-tailed Class Incremental Learning with Vision-Language Models |
|
| [P46] ZeKai Li, Yufen Sun FiGA: Fidelity-Aware Gaussian Avatars for Human Reconstruction |
|
| [P47] Peng Chen, Jingyuan Xu, Li Mingrui, Wang HongYu TA-GS:Transient-Aware Gaussian Splatting for Robust Static 3D Reconstruction |
|
| [P48] Ruopeng Zhao, Yafeng Zhao, Zhijie Song, Gang Shi Efficient Panoramic 3D Gaussian Splatting with Gradient Optimization and Scene Regularization |
|
| [P49] Jinyu Gu, Haipeng Liu, Meng Wang, Yang Wang PIDiff: Image Customization for Personalized Identities with Diffusion Models |
|
| [P50] Seong-Eun Hong, JuYeong Hwang, RyunHa Lee, HyeongYeop Kang ORACLE: Orchestrate NPC Daily Activities using Contrastive Learning with Transformer-CVAE |
|
| [P51] Hao Wang, Qingshan Xu, Hongyuan Chen, Tieru Wu, Rui Ma PGAHum: Prior-Guided Geometry and Appearance Learning for High-Fidelity Animatable Human Reconstruction |
|
| [P52] Yinghui Wang, Xinyu Zhang, Peng Du GACO-CAD: Geometry-Augmented and Conciseness-Optimized CAD Model Generation from Single Image |
|
| [P53] Jiachen Li, Rui Xing, Chunjing Wang, Mingle Zhou, Min Li, Gang Li, Xueying Qin Rethinking the Implicit Segmentation of 3D Object Tracking under Vision Foundation Model |
|
| [P54] Yao Liu, Yangjun Ou, Li Mi FiTBench: Benchmark for Scene Graph Anticipation with Fine-grained Text Cues |
|
| [P55] Zihan Gu, Linquan Yang, Xiyan Gan Adaptive Iterative Point Cloud Denoising with Signed Distance Function Estimation |
|
| [P56] Jie Pan, Ling Lei, Tianhang Tang, Shaobing Gao, Yiguang Liu VividTalker: Generalized and Stable 3D Gaussian-based Talking Head Synthesis |
|
| [P57] Yuanzhen Li, Leran Ye, Fubao Yang, HongZhi Liu, Fengli Yang, Xiaoxiao Wang, Yue Zhao Document Shadow Removal via Pixel-Adaptive Illumination Residual Learning |
|
| [P58] Siyu Chen, Yunhan Shang, Jing Ma, Yun Su Stablediff-Fabric: Controllable Generation of Ultra-Detailed Textile Images via Diffusion Models and Microstructure-Annotated Dataset |
|
| [P59] Feng Zhou, Yanrui Sun, Ju Dai, Shihao Zou, Senzhe Xu, Wei Zhou, Yu-Kun Lai, Paul Rosin MaTMotion: Text-Driven Human Motion Generation Based on the Mamba-Transformer |
|
| [P60] Xiaogang Wang, Yuncong Liu, Boran Zhang, Kai Xu Reconstructing 3D Wireframes from Point Clouds by Decoding Three Orthographic Blueprints |
|
| [P61] Feinan Cheng, Dongliang Xu, Wenli Nong, Zhiheng Zhang, Ang Liu, Tianyu Wang, Yue Yao No Training, Better Flights: Test-Time Scaled VLMs for UAV Navigation |
|
| [P62] Xiaoyan Cong, Haitao Yang, Liyan Chen, Kaifeng Zhang, Li Yi, Chandrajit Bajaj, Qixing Huang 4DRecons: Monocular Dynamic Reconstruction with Geometrical and Topological Regularization |
|
| [T11] Mining Tan, Weiming Dong, Fuzhang Wu Unified Adverse Weather Image Restoration via One-Step MoE Flow |
|
| [T12] Yujie Yuan, Leif Kobbelt, Jiwen Liu, Yuan Zhang, Pengfei Wan, Yu-Kun Lai, Lin Gao 4Dynamic: Text-to-4D Generation with Hybrid Priors |
|
| [T13] Yujie Yuan, Leif Kobbelt, Tong Wu, Weicai Ye, Xintao Wang, Pengfei Wan, Yu-Kun Lai, Lin Gao NVS-Video: Novel View Synthesis for Monocular Video with Local Dynamic Epipolar Attention and Video Diffusion Models |
|
| [T14] Jihoon Kim, Sanghun Park Surface-dependent Comparison of Pose Estimation Pipelines for 3D Gaussian Splatting |
|
| [T15] ChangKyu Lee, Yun Hyoyeon Zone-Based Real-Time Indoor Evacuation Guidance Using Visual Media Analysis and 3D Spatial Representation |
|
| [T16] Jiyoung Park, Young J. Kim Ray-centric Gradient Decomposition for Densifying 3D Gaussians |
|
| [T17] Haocheng Yang Gradient-Guided Light Field Angular Super-Resolution via global-local features enhancement |
|
| [T18] Patt Phurtivilai, Lei Yang, Leyang Huang, Yinqiang Zhang DensifyBeforehand: LiDAR-assisted Content-aware Initialization for Efficient 3D Gaussian Splatting |
|
| [T19] Yijing Wa, Zihan Hua, Chenle Xu, Yang Li, Changbo Wang HVIP: a Hybrid VIrtual Production pipeline for short video with LED-wall and programmable lighting |
|
| [T20] Zechu Zhang, Mengda Xie, Jinyu Wen Interactive Tooth Alignment via Text Prompts and Dental Arch Editing |
|
| 17:15 - 17:40 | Move to Gwanggaeto Hall |
| 17:40 - 18:00 | Virtual Production Global Showcase @ Gwanggaeto Hall 15F |
| 18:30 - 21:00 | Conference Banquet @ Gwanggaeto Hall B2 (Chair: Yun Jang) |
| Day 3 | Sunday, April 12, 2026 |
| 08:30 - 09:00 | Registration @ 12F, Daeyang AI Center |
| 09:00 - 10:00 | Keynote Speech III - Prof. Markus Gross: Artificial Intelligence for Making Films (Chair: Soo-Mi Choi) |
| 10:00 - 10:20 | Coffee Break |
| 10:20 - 12:00 | Paper Session 7: Physics, Rendering and Simulation (Chair: Seung-wook Kim) |
| Zhi Zhang, Meng Gai, Sheng Li Visual Acuity Consistent Foveated Rendering Towards Retinal Resolution |
|
| Haoyu Zhu, Yi Zhang, Lei Yao, Lap-Pui Chau, Yi Wang MASS: Mesh-inellipse Aligned Deformable Surfel Splatting for Hand Reconstruction and Rendering from Egocentric Monocular Video |
|
| PENG PENG YE YONGLONG Physically Based Boiling Simulation with Thermally Driven Dynamic Nucleation |
|
| Short Break (10 min) | |
| Cen Yunchi, Hanchen Deng, Qifan Zhang, Frederick W. B. Li, Bailin Yang, Xiaohui Liang A High-Efficiency Physics-Based Differentiable Renderer for Smoke Reconstruction |
|
| Jiawei H, Shaokun Zheng, Kun Xu, Yoshifumi Kitamura, Jiaping Wang Efficient Monte Carlo Rendering of Implicit-Shaped Volumetric Emitters |
|
| Xiaohan Sun, Carol O'Sullivan From Far and Near: Perceptual Evaluation of Crowd Representations Across Levels of Detail |
|
| 12:00 - 13:00 | Lunch @ BigBear (2F) |
| 13:00 - 13:40 | Invited Session 2: AI in Visual Media (Chair: Taesoo Kwon) |
| Prof. Richard Zhang (Simon Fraser University, Canada) Functional AI and Foundation Model for 3D Building and Construction |
|
| Prof. Carol O'Sullivan (Trinity College Dublin, Ireland) Can We Still Believe Our Eyes? — When AI Fools Us (and When It Doesn't) |
|
| 13:40 - 14:25 | Paper Session 8: Medical and Medical Imaging (Chair: Ri Yu) |
| lanrong bian, Ying Long DU-Net: Dual-Level Uncertainty-Aware Few-Shot Medical Image Segmentation via Evidential Deep Learning |
|
| Jinhua Liu, Wen Tang, Yongsheng Shi, Dongjin Huang Neural Radiance Fields for 3D Polyp Segmentation of Deformable Tissues in Endoscopy |
|
| Shuning He, Da Ren, Haiwei Pan, Kejia Zhang, Qing Li Rethinking Medical VQA Models: Towards Data-Efficient Learning |
|
| 14:25 - 14:40 | Coffee Break |
| 14:40 - 15:40 | Invited Session 3: Advances in Visual Computing, Simulation, and XR (Chair: Jae-In Hwang) |
| Prof. Taesoo Kwon (Hanyang University, Korea) Fast and Adaptive Locomotion with Centroidal and Momentum-Based Control |
|
| Prof. Youngmin Kim (Seoul National University, Korea) Image-Guided Geometric Stylization of 3D Meshes |
|
| Prof. Ri Yu (Ajou University, Korea) From Pixels to Patients: Reconstructing and Understanding Human Motion from Video |
|
| Prof. Hyungseok Kim (Konkuk University, Korea) Metaverse : Platform for Sharing Experiences |
|
| Prof. Sunjeong Kim (Hallym University, Korea) Multisensory Cues in XR: How Scent Changes Perception, Navigation, and User Experience |
|
| Prof. Myung Geol Choi (The Catholic University of Korea, Korea) Real-Time Crowd Density Management with Simulation and Real-World Data |
|
| 15:40 - 16:00 | Closing Session (Chair: Soo-Mi Choi) |
Campus Map
Keynote Speakers

Prof. Seung-Hwan Baek, POSTECH, South Korea
Title:
Computational Illumination for High-dimensional Visual Computing
Abstract:
Traditional visual computing has primarily focused on modeling the transport of RGB light intensity in image formation, enabling perception and reconstruction tasks at a human-level understanding. In this talk, I will introduce our recent work on computational illumination-active imaging systems that exploit richer properties of light, including spectrum, polarization, and phase. These systems open up new possibilities for high-dimensional visual computing, such as 360 degree 3D imaging, full-space holography, hyperspectral 3D reconstruction, real-time polarimetric imaging, and robust robot vision in complex scenes.
Speaker's Biography:
Seung-Hwan Baek is an Associate Professor in the Department of Computer Science and Engineering at POSTECH and is jointly affiliated with the Graduate School of AI. He leads the POSTECH Computational Imaging Group and serves as co-director of the POSTECH Computer Graphics Lab. Prof. Baek received his Ph.D. in Computer Science from KAIST and was a postdoctoral researcher at Princeton University. His research lies at the intersection of computer graphics, computer vision, AI, and optics, with a focus on capturing, modeling, and interpreting high-dimensional visual data shaped by the complex interplay of light, material, and geometry. His work has broad applications in mobile imaging, robotics, autonomous systems, AR/VR displays, and scientific instrumentation. He has been recognized with several honors, including the Asiagraphics Young Researcher Award, the Frontiers of Science Award from the International Congress of Basic Science, the Outstanding Ph.D. Thesis Award in IT from the Korean Academy of Science and Technology, the SIGGRAPH Asia Doctoral Consortium Award, the Microsoft Research Asia Ph.D. Fellowship, Naver Ph.D. Fellowship, and best application paper award and best demo award at ACCV 2014.

Prof. Beibei Wang, Nanjing University, China
Title:
The Evolution of Material Representation: From Physically-Based to Neural Networks
Abstract:
The vividness and realism of the real world come from its rich and diverse geometric structures and appearances. Among these elements, the representation of appearance is essential for achieving realism. For many years, physically-based material models have been the standard in computer graphics. However, a noticeable trend has emerged in recent years: a shift from physical to neural material representations. This presentation will explore the evolution from physical to neural material modeling, review related research conducted by our team, and offer insights into future directions for material representation.
Speaker's Biography:
Beibei Wang is a professor in the School of Intelligence Science and Technology at Nanjing University. Her research interests include appearance modeling, realistic rendering, and neural rendering. She got her B.S. in 2009 and her Ph.D. in 2014, both from Shandong University. Additionally, she spent two years as a joint Ph.D. student at Telecom ParisTech from 2012 to 2014. Following her doctoral studies, Beibei worked as a postdoctoral fellow with the INRIA (Grenoble) MAVERICK team from 2015 to 2017. She also contributed to the development of Disney Infinity while working at Studio Gobo (UK) from 2014 to 2015. She has published about thirty papers in top-tier journals and conferences, including ACM TOG, SIGGRAPH (Asia), CVPR, and ICCV. She serves on the editorial boards of the Journal of Computer Graphics Techniques and Computer Graphics Forum. She served as the Program Co-Chair of EGSR 2026 and a member of the SIGGRAPH 2025 Sorting Committee.

Prof. Markus Gross, ETH Zürich and The Walt Disney Studios
Title:
Artificial Intelligence for Making Films
Abstract:
Recent advances in machine learning and artificial intelligence have the potential to disrupt many aspects of the traditional filmmaking process both for life action and for animation productions. At Disney Research Studios (DRS) more than 50 researchers are rethinking the film production and distribution pipeline with the help of AI in order to increase production efficiency and to support the creativity of our storytellers. To fulfill its mission, DRS closely aligns its portfolio with the technology innovation needs of the 6 major film studios of the company and continuously injects novel inventions into Disney’s film production. In this talk I will take you through the Walt Disney Studios technology innovation process and show how machine learning is already being used in film production. Examples include digital humans, virtual production technologies, rendering and animation, image quality enhancement, and much more.
Speaker's Biography:
Markus Gross is the Chief Scientist of the Walt Disney Studios and a professor of Computer Science at ETH Zürich. He is one of the leading authorities in Visual Computing, Computer Animation, Digital Humans, Virtual Reality, and AI. In his role at Disney, he leads the Studio segment’s research and development unit where he and his team are pushing the forefront of technology innovation in service of the filmmaking process. Gross has published over 500 scientific papers and holds over 100 patents. His work and achievements have been recognized widely including two Academy Awards and the ACM SIGGRAPH Steven Anson Coons Award. Gross is member of multiple academies of sciences and of the Academy of Motion Pictures Arts and Sciences.